

Chi-Squared Test
The Chi-Squared test is used to determine if a sample comes from a population with a specific distribution. This test is applied to binned data, so the value of the test statistic depends on how the data is binned. Please note that this test is available for continuous sample data only.
Although there is no optimal choice for the number of bins (k), there are several formulas which can be used to calculate this number based on the sample size (N). For example, EasyFit employs the following empirical formula:

The data can be grouped into intervals of equal probability or equal width. The first approach is generally more acceptable since it handles peaked data much better (you can change the binning method in the Fitting Options dialog). Each bin should contain at least 5 or more data points, so certain adjacent bins sometimes need to be joined together for this condition to be satisfied.
Definition
The Chi-Squared statistic is defined as
 ,
,where Oi is the observed frequency for bin i, and Ei is the expected frequency for bin i calculated by
 ,
,where F is the CDF of the probability distribution being tested, and x1, x2 are the limits for bin i.
Hypothesis Testing
The null and the alternative hypotheses are:
- H0: the data follow the specified distribution;
- HA: the data do not follow the specified distribution.
The hypothesis regarding the distributional form is rejected at the
chosen significance level (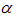 ) if the test
statistic is greater than the critical value defined as
) if the test
statistic is greater than the critical value defined as

meaning the Chi-Squared inverse CDF with k-1 degrees of freedom and a significance
level of . Though the number of degrees of freedom can
be calculated as k-c-1 (where c is the number of estimated parameters), EasyFit
calculates it as k-1 since this kind of test is least likely to reject the fit in
error.
The fixed values of (0.01, 0.05 etc.) are generally
used to evaluate the null hypothesis (H0) at various significance levels.
A value of 0.05 is typically used for most applications, however, in some critical
industries, a lower value may be applied.
P-Value
The P-value, in contrast to fixed values, is calculated based
on the test statistic, and denotes the threshold value of the significane level in the sense that
the null hypothesis (H0) will be accepted for all values of
less than the P-value. For example, if P=0.025, the null hypothesis
will be accepted at all significance levels less than P (i.e. 0.01 and 0.02),
and rejected at higher levels, including 0.05 and 0.1.
The P-value can be useful, in particular, when the null hypothesis is rejected at all predefined significance levels, and you need to know at which level it could be accepted.
EasyFit displays the P-values based on the Chi-Squared test statistics (χ2) calculated for each fitted distribution.
www.mathwave.com